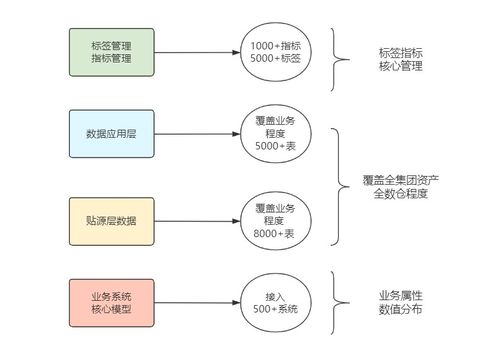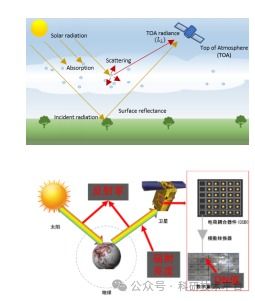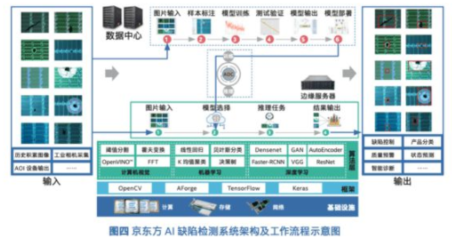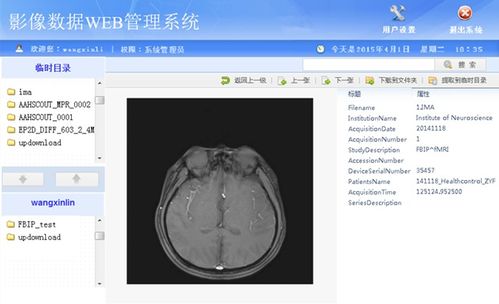
随着信息技术的飞速发展,我们已步入一个数据爆炸的时代。海量、多样、高速的数据——即“大数据”——正成为驱动社会经济发展的重要引擎。有效处理和利用这些数据,关键在于掌握一系列核心技术和科学的数据采集方法。
一、大数据处理的关键技术
大数据处理是一个复杂的过程,通常涉及数据的采集、存储、计算、分析和可视化等多个环节。其中,以下关键技术构成了大数据处理的核心支撑:
1. 分布式存储技术:
传统集中式存储已无法满足海量数据的需求。以Hadoop的HDFS(分布式文件系统)为代表的分布式存储技术,将数据分割成块,分散存储在多台廉价服务器上,实现了高可靠性、高扩展性和高吞吐量的数据存储。
2. 分布式计算技术:
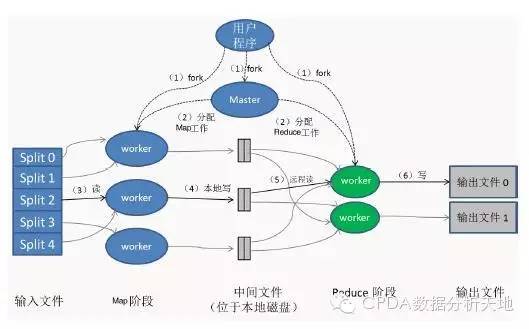
面对PB级别的数据,单机计算能力捉襟见肘。MapReduce、Spark、Flink等分布式计算框架应运而生。它们将大规模计算任务分解成许多小任务,分配到集群中的多个节点并行处理,最后汇果,极大地提升了计算效率。其中,Spark凭借其内存计算的特性,在迭代计算和实时流处理方面表现尤为出色。
3. 数据挖掘与分析技术:
存储和计算的最终目的是挖掘数据价值。这涉及到机器学习、深度学习、统计分析、自然语言处理等一系列分析技术。通过聚类、分类、回归、关联规则分析等算法,可以从看似无序的数据中发现规律、预测趋势、识别模式,为决策提供支持。
4. 数据管理与治理技术:
确保数据质量、安全与合规至关重要。这包括元数据管理、数据血缘追踪、数据质量管理、数据安全与隐私保护(如脱敏、加密、访问控制)等技术。良好的数据治理是数据资产价值得以持续释放的保障。
5. 流处理与批处理融合技术:
大数据处理既有对历史数据进行批量分析的需求,也有对实时产生的数据流进行即时响应的需求。Lambda架构和Kappa架构等设计模式,以及像Flink这样支持流批一体的处理引擎,使得企业能够同时应对这两种场景,实现从“事后分析”到“实时智能”的跨越。
二、大数据采集的主要方法
“巧妇难为无米之炊”,高质量的数据采集是后续所有处理环节的基础。大数据采集的主要方法可以归纳为以下几类:
1. 系统日志采集:
这是互联网企业最常用的方法。通过在网站、APP或服务器中嵌入特定的数据采集代码(如Google Analytics、百度统计的JS代码,或自研的SDK),可以自动、持续地收集用户的行为日志、性能日志、业务日志等。这些日志文件通常通过Flume、Logstash等工具实时采集并传输到数据中心。
2. 网络数据爬取:
对于公开的互联网信息,如新闻、社交媒体内容、商品信息、公开报告等,可以通过编写网络爬虫(Spider)程序,自动抓取指定网站的结构化或半结构化数据。在使用此法时,必须严格遵守网站的Robots协议和相关法律法规,尊重数据版权与个人隐私。
3. 数据库直接同步:
企业内部的业务数据,如交易记录、客户信息、库存数据等,通常存储在MySQL、Oracle等传统关系型数据库中。可以使用Sqoop、DataX等数据同步工具,或通过数据库的日志复制功能(如MySQL的Binlog),将这些数据高效、增量地导入到大数据平台(如Hadoop、数据仓库)中。
4. 传感器与物联网采集:
在工业制造、智能交通、环境监测、智慧农业等领域,通过部署大量的物理传感器、RFID、GPS等设备,可以持续不断地采集温度、湿度、位置、压力、图像等物理世界的数据,并通过物联网网络汇聚到数据处理中心。
5. 第三方数据购买与交换:
企业也可以通过合规渠道,向专业的数据提供商购买或交换所需的数据,如行业报告、市场调研数据、信用数据等,以补充自身数据维度的不足。
6. 应用程序接口调用:
许多平台和服务(如社交媒体API、地图API、支付API、天气API)提供了标准化的数据接口。通过合法授权和调用这些API,可以安全、结构化地获取所需的外部数据。
###
大数据处理是一个系统工程,其核心在于将分布式存储与计算、智能分析与科学的数据采集方法有机结合。从底层的基础设施到上层的分析应用,技术的选择和架构的设计需要紧密围绕具体的业务需求和数据特点。在数据采集与处理的全程,必须将数据安全、隐私保护和合规性置于首位。唯有如此,才能真正驾驭数据洪流,将海量数据转化为宝贵的知识和智能决策力,驱动创新与增长。