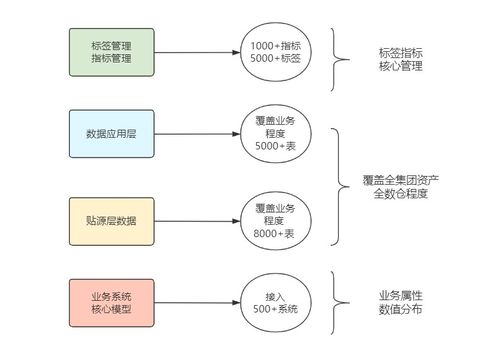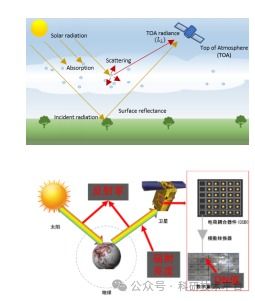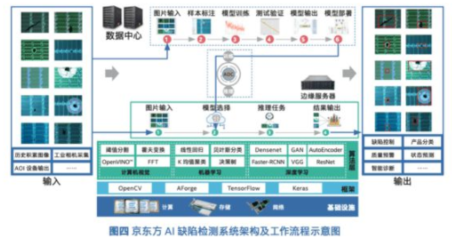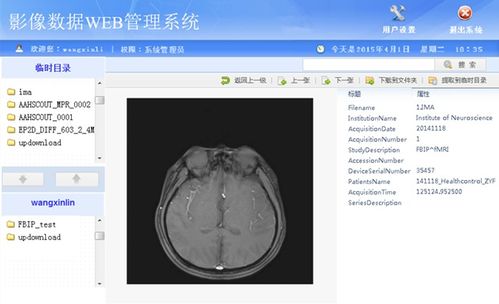
在当今以数据驱动的数字化时代,软件系统的核心价值往往不再局限于功能实现,而在于其处理、分析和利用数据的能力。数据处理,作为软件架构设计中至关重要的支柱,是连接原始信息与业务洞察的桥梁。本文将系统性地探讨软件架构中数据处理的关键环节、设计原则与演进趋势。
一、数据处理在架构中的核心地位
数据处理是指对原始数据进行采集、存储、转换、分析和呈现,以提取有价值信息并支持决策的一系列技术活动。在软件架构中,它并非孤立模块,而是贯穿于整个系统的血脉。一个设计精良的数据处理架构能确保数据的准确性、一致性、时效性和安全性,从而支撑起上层应用的高效运行与智能决策。
二、数据处理的核心环节与架构模式
- 数据采集与摄入:这是数据生命周期的起点。架构需考虑如何从多样化来源(如数据库、日志、传感器、API)实时或批量地收集数据。常见模式包括事件驱动架构(如使用Kafka、RabbitMQ的消息队列)和ETL(提取、转换、加载)管道。设计时需权衡吞吐量、延迟与可靠性。
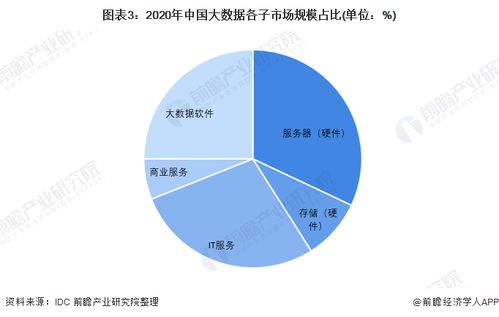
- 数据存储与管理:根据数据特性和访问模式,选择合适的存储技术。结构化数据可采用关系型数据库(如MySQL、PostgreSQL);半结构化或非结构化数据可选用NoSQL数据库(如MongoDB、Cassandra)或对象存储(如AWS S3)。数据湖(Data Lake)和数据仓库(Data Warehouse)的架构模式,分别适用于原始数据存储和结构化分析场景。
- 数据处理与计算:此环节涉及数据的清洗、转换、聚合与分析。批处理架构(如Apache Hadoop、Spark)适合海量历史数据的离线计算;流处理架构(如Apache Flink、Storm)则支持实时数据流的连续处理。现代架构常采用Lambda或Kappa架构,以兼顾批流一体化处理。
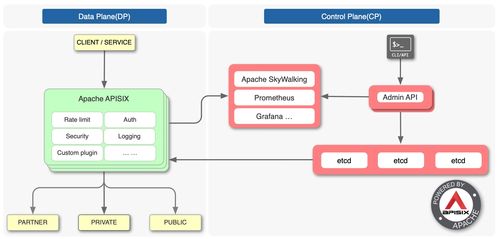
- 数据服务与输出:处理后的数据需通过API、数据可视化工具或机器学习模型服务等方式提供给终端用户或下游系统。微服务架构中的专用数据服务层,能够确保数据的安全暴露与高效访问。
三、关键设计原则
• 可扩展性:架构应能水平扩展以应对数据量的增长,如通过分片、分布式计算实现。
• 容错与可靠性:采用副本、检查点、事务机制等保障数据不丢失与处理连续性。
• 一致性权衡:根据业务需求,在强一致性、最终一致性等模型间做出合理选择。
• 安全性:贯穿始终的数据加密、访问控制与合规性设计。
• 可维护性:模块化设计、清晰的数据流水线与完善的元数据管理。
四、演进趋势与未来展望
随着云原生、人工智能与边缘计算的普及,数据处理架构正持续演进。云原生数据平台(如Snowflake、Databricks)提供了弹性和托管服务;数据网格(Data Mesh)倡导去中心化的领域导向数据所有权;而实时AI推理与边缘数据处理则推动着架构向更低延迟、更智能的方向发展。数据处理架构将更加自动化、智能化,并与业务场景深度无缝融合。
数据处理架构的设计是一项复杂的系统工程,需要在业务需求、技术约束与未来演进间找到平衡。优秀的架构师不仅需要掌握多样化的技术栈,更要深刻理解数据背后的业务逻辑,从而构建出既稳健又灵活的数据处理支柱,最终驱动软件系统从简单的信息处理器进化为智慧的决策引擎。