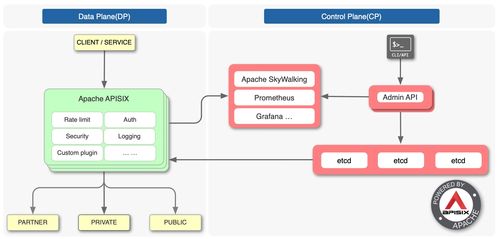
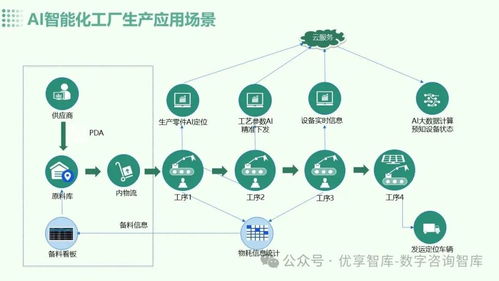
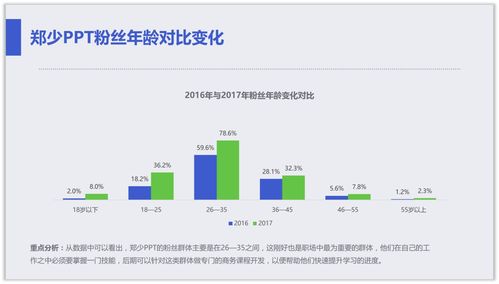
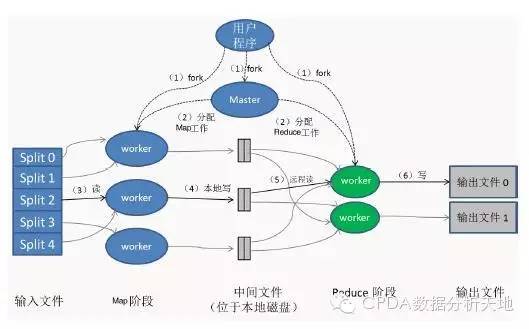
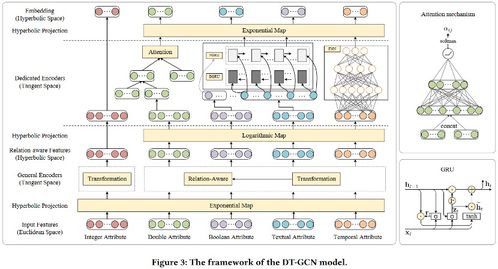
在CIKM 2021上提出的DT-GCN(Data Type-aware Graph Convolutional Network)模型,是一种创新的知识图谱表示学习方法,其核心在于将实体与关系映射到双曲空间(具体为庞加莱球模型)中,并显式地建模和处理知识图谱中不同数据类型(如数值型、分类型、文本型等)对关系表示的影响。数据处理作为模型训练与评估的先决条件,其质量与流程设计直接关系到模型的最终性能。本文将详细阐述DT-GCN模型所需的数据处理流程。\n\n### 1. 数据来源与原始结构\n数据处理始于原始知识图谱数据。通常,一个知识图谱可以形式化为一个三元组集合 \\( \\mathcal{G} = \\{ (h, r, t) \\} \\),其中 \\( h \\) 是头实体,\\( r \\) 是关系,\\( t \\) 是尾实体。除了三元组结构外,DT-GCN的关键输入是附着在实体和/或关系上的属性数据。这些属性具有不同的数据类型(Data Type),例如:\n- 数值型:如人物的年龄、公司的市值(连续或离散数值)。\n- 分类型:如人物的国籍、公司的行业类别(离散标签)。\n- 文本型:如实体的描述文本、关系的中文释义。\n原始数据可能来源于结构化知识库(如Wikidata、YAGO)、领域特定数据库或通过信息抽取技术从非结构化文本中构建。\n\n### 2. 核心数据处理步骤\nDT-GCN的数据处理旨在为模型准备两类输入:图结构数据和属性特征数据。\n\n步骤一:图结构数据预处理\n1. 三元组划分:将整个知识图谱的三元组集合 \\( \\mathcal{G} \\) 划分为训练集、验证集和测试集。通常采用随机划分或按时间划分(适用于时序图谱),并需确保实体和关系在分割后不会完全消失在训练集中(即考虑连通性)。\n2. 负采样生成:为训练过程中的对比学习或负采样损失函数准备负例。对于每个训练正例 \\( (h, r, t) \\),通过随机替换头实体或尾实体(有时也替换关系)来生成负例 \\( (h', r, t) \\) 或 \\( (h, r, t') \\),确保生成的三元组不在已知的正例集合中。\n3. 图构建:基于训练集三元组,构建实体之间的关系邻接矩阵或邻居列表,用于后续图卷积操作。DT-GCN可能考虑多跳邻居信息。\n\n步骤二:属性特征提取与类型化编码\n这是DT-GCN区别于传统模型的关键步骤,旨在将不同数据类型的属性转化为统一的特征向量,同时保留其类型信息。\n1. 数据清洗与对齐:\n - 处理缺失值:对于缺失的属性,可以采用特定值填充(如数值型用均值,分类型用特殊标签“UNK”),或直接将其特征设为零向量。\n - 实体/关系ID与属性对齐:确保每个实体ID和关系ID都能关联到其对应的属性字典或记录。\n2. 分类型属性编码:\n - 使用独热编码(One-hot Encoding)或可学习的嵌入层(Embedding Layer)将每个分类标签映射为一个稠密向量。\n - 对于具有层次结构的分类属性(如“地理位置:中国>北京>海淀区”),可以考虑编码其层次信息。\n3. 数值型属性编码:\n - 标准化/归一化:将连续值缩放到固定范围(如[0, 1])或进行标准化(均值为0,方差为1),以加速模型收敛。\n - 离散化(可选):有时将连续值分桶处理为离散类别,再按分类型属性处理。\n - 直接映射:通过一个可学习的线性或非线性层(如MLP)将标量数值映射为稠密向量。\n4. 文本型属性编码:\n - 使用预训练的语言模型(如BERT、RoBERTa的CLS token向量)或静态词向量模型(如Word2Vec、GloVe)获取文本的句嵌入或词嵌入池化后的向量表示。\n5. 特征融合与类型标识:\n - 对于一个实体或关系,可能拥有多种类型、多个属性的特征。需要将这些特征向量进行融合,常见方法包括拼接(Concatenation)、加和(Summation)或注意力机制加权融合。\n - 关键步骤:为每个属性特征向量附加一个数据类型标识符。DT-GCN模型中设计了一个类型感知的转换模块,该标识符用于指导模型对不同来源和类型的特征进行差异化的变换和处理。这可以通过为不同类型分配不同的可学习变换矩阵来实现。\n\n步骤三:输入数据组装\n为模型组装的每批训练数据包含:\n- 一批正例三元组:形状为 \\( (batch\_size, 3) \\) 的张量,包含头实体ID、关系ID、尾实体ID。\n- 对应的属性特征:根据实体ID和关系ID索引得到的,已经过类型化编码和融合后的特征矩阵。\n- 对应的负例三元组(用于训练时计算损失)。\n\n### 3. 注意事项与挑战\n- 异构性处理:知识图谱中不同实体类型的属性 schema 差异巨大,需要灵活的数据管道支持。\n- 特征维度统一:不同类型属性编码后的向量维度可能不同,需要在融合前通过投影层统一维度,或在模型设计时处理。\n- 计算效率:文本编码(特别是使用大型LM)可能成为计算瓶颈,可以考虑离线编码或缓存策略。\n- 数据泄露:在划分数据集和进行特征编码(如标准化计算均值方差)时,必须严格使用训练集数据来计算统计量,避免信息从验证集/测试集泄露到训练过程。\n\n### 结论\nDT-GCN模型的数据处理流程是一个将异构、多类型的知识图谱原始数据转化为结构化、类型标识明确的数值化输入的系统工程。它不仅仅是为模型准备“燃料”,其本身也深刻体现了模型“数据类型感知”的核心思想。精心设计的数据处理流程,能够最大限度地保留原始数据中的语义和类型信息,为后续在双曲空间中进行高效、准确的表示学习奠定坚实的基础。
基于双曲空间的DT-GCN 一种数据类型感知的知识图谱表示学习模型的数据处理流程
如若转载,请注明出处:http://www.tizicun.com/product/6.html
更新时间:2026-06-18 14:58:47
产品列表
PRODUCT
----------------